When using and monitoring AWS for EC2 instances and their attached EBS volumes there are a couple of very important metrics to keep an eye on which can have enormous performance and availability implications. In particular I’m writing about General Purpose EC2 instance running in standard mode (eg. T2, T3 and T3a at the time of writing) and General Purpose EBS (gp2) because these are very common low-mid spec instances and the default disk storage type. If you’re already using one of the other EC2 or EBS types, chances are you’re already aware of some of the issues I’ll discuss below and those other products are designed to manage CPU and disk resources in a different load targeted way. These metrics are important because they report on the way these AWS resources (otherwise designed to mimic a real hardware) operate in a very different way. Note that while CPU credit reports are shown in the AWS web console for an EC2 instance under it’s Monitoring tab (and so people tend to see it), the EBS credit reports are not. To see these you need to find the EBS volume(s) attached to an EC2 instance (this is linked from the EC2 Description tab) and then look at the Monitoring tab for each EBS volume.
EC2 CPUCreditUsage and CPUCreditBalance
CPU credits are use to limit how much CPU is available to a EC2 instance - and while you have CPU credits spare an EC2 instance will just run as you expect, but at the point you run out the virtual CPU simply stops being available and the system slows down.
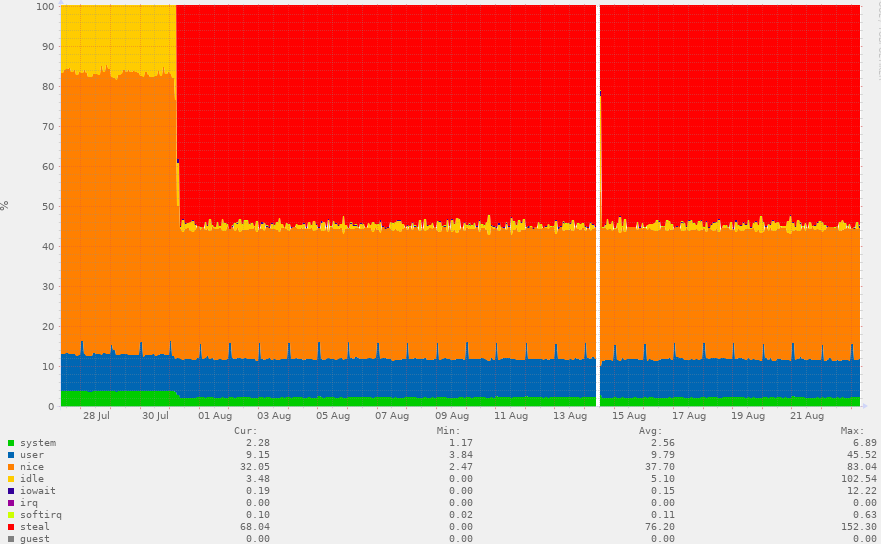
Symptoms will be a higher load and a laggy responses to things like server responses and command-line execution. If you’re monitoring the server CPU you may also see CPU Steal appearing - for example the following report show CPU steal kicking in and effectively blocking some use of the CPU:
 Quoting the AWS docs:
Quoting the AWS docs:
- “A CPU credit provides for 100% utilization of a full CPU core for one minute.”
- “Each burstable performance instance continuously earns (at a millisecond-level resolution) a set rate of CPU credits per hour, depending on the instance size.”
The “Earning CPU Credits” documentation shows you details for CPU credits for each type of general purpose instance. Some important notes:
- On boot (this is limited, you can’t just reboot every 20 minutes forever, though perhaps for a short encapsulated task this could be a strategy) EC2 instances receive a bunch of Launch Credits scaled by instance type. This means that an instance might appear to be running perfectly well just after you provision an instance only to fall over hours/days/weeks later when it turns out your system is over the baseline performance and has been gradually eating up this stash of CPU credits.
- There is an option to switch to “unlimited mode” but this should only be used with extreme caution and lots of monitoring as it simply means that AWS will allocate as much CPU credits are needed and then charge you for the balance. This is one of those ways that huge AWS charges can be accrued by accident.
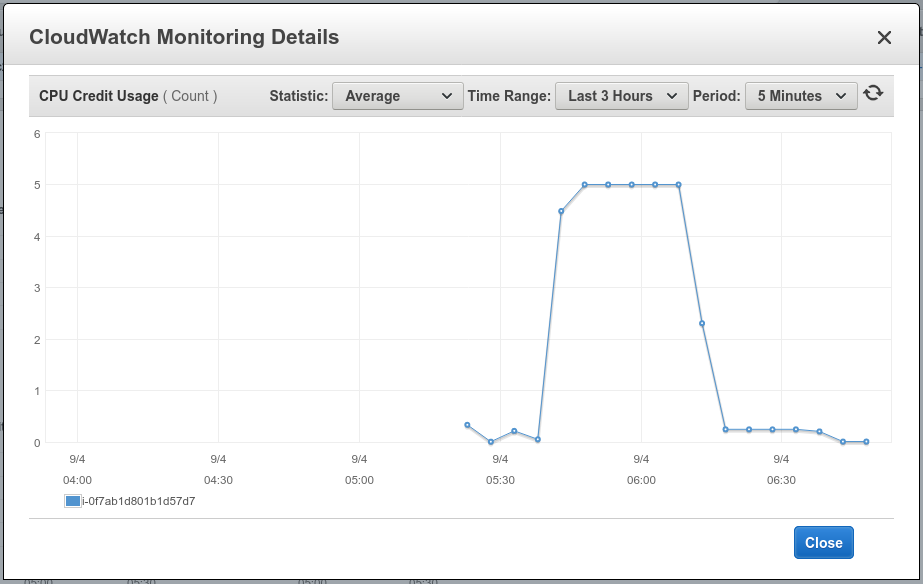
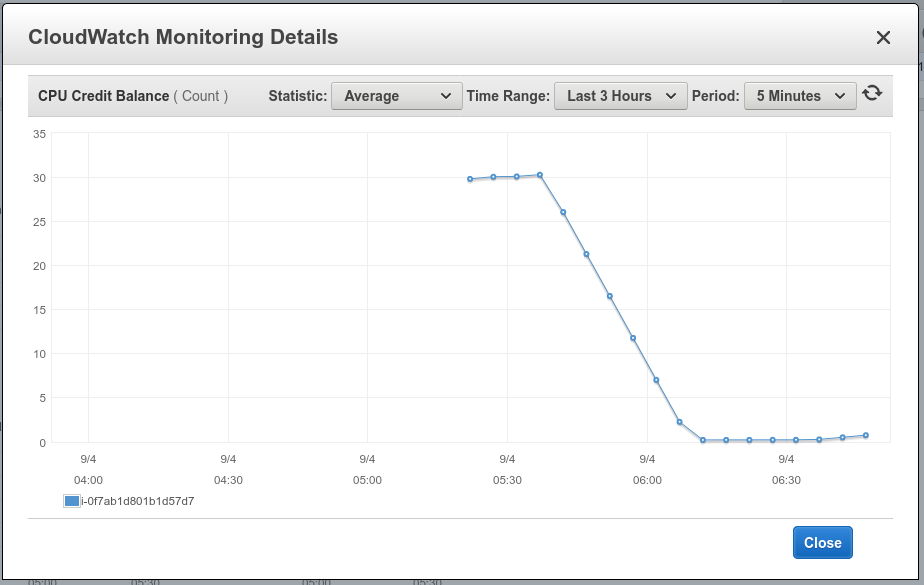
When a system starts to run out of CPU credit you can see this using the CloudWatch monitors in the AWS console - for example the following reports show CPU Credit Usage shooting up with a high load, and the corresponding drop in the CPU Credit Balance. As soon as the balance runs out the usage drops simply because there are none left to use - at this stage the CPU credits are exhausted.
EBS BurstBalance, VolumeReadOps and VolumeWriteOps
Two key statements from the “Amazon EBS volume types” are: “Between a minimum of 100 IOPS (at 33.33 GiB and below) and a maximum of 16,000 IOPS (at 5,334 GiB and above), baseline performance scales linearly at 3 IOPS per GiB of volume size.” This means that the provisioned IOPS for the default EBS volume size (which is 8GB) is the minimum - which is 100IOPS. It’s very easy to reach this limit with a moderate disk load. And this from “I/O Credits and burst performance”: “When your volume requires more than the baseline performance I/O level, it draws on I/O credits in the credit balance to burst to the required performance level, up to a maximum of 3,000 IOPS. When your volume uses fewer I/O credits than it earns in a second, unused I/O credits are added to the I/O credit balance. The maximum I/O credit balance for a volume is equal to the initial credit balance (5.4 million I/O credits).” Which means that (like CPU credits) the gp2 EBS volumes provide burstable performance - and when those burst credits are used up the disk simply slows down in a way which can cause a system to rapidly become non-responsive to the point it may need to be hard restarted. Critically with a healthy un-throttled CPU but a IOPS-throttled disk a system can quickly reach a state of being effectively deadlocked - but the good news is that EBS performance is very easy to scale by increasing the size of the volume (see below).
Scaling Fixes
Running out of resources can be managed by optimising and tuning code and configuration in some cases, while in others there may simply be more resources required. With virtual machines of course the nice thing is that this just requires paying for more resources - and considering the above metrics may help target which resources to pay for. Increasing EC2 Instance Types directly increases the amount of CPU and memory available, but does require an EC2 restart. EC2 instance increments can quickly become expensive as each increment doubles the previous spec and price. Spreading disk IO across more physical disks is a known strategy for high disk IO requirements - and can be emulated setting up virtual disk RAID arrays in AWS. However because EBS gp2 simply scales baseline IOPS linearly with disk size the easiest approach can be simply to make a larger disk and grow the filesystem. On a relatively recent EC2 instance (with growpart - part of the cloud-guest-utils package in debian/ubuntu) it’s possible to make these changes live and scale them up gently until the disk performance meets the load of the system (and so minimise extra cost).
Final Thoughts
Exactly how running out of either CPU or EBS credits affects you is very much load dependent. In practice I’ve found that running out of EBS credits tends to hit a lot harder than CPU where there is any sort of concurrent disk usage. When disk slows down (which normal disk doesn’t tend to do, or at least nowhere near to the extent that EBS throttled disk does) it’s EC2 can become completely unresponsive and may need a hard restart as you end up behind a massive queue of disk IO operations. With so many system interactions relying on otherwise trivial disk writes (eg. things like text editors opening backup files, writing to logs, shell history files) once EBS credits are exhausted (with a sustained disk IO load) a system can become effectively deadlocked. On the other hand running out of CPU credits seems to be sustainable if you do not mind a little slowness, an EC2 running in this state does not tend to end up as unresponsive as an EBS credit starved system. In particular the system for the report above showing lots of CPU steal is running very responsively and getting all it’s processes run within acceptable time but when that same system ran out of EBS credits processes fell over and regular jobs ran into each other leaving large gaps in the backend data. Monitoring all of these metrics can allow a more informed approach to tuning application resource usage and/or scaling the resources purchased from AWS.